単方向循環リスト
前章で、連結リストには4タイプあると書きました。それは、以下の4つです。
- 単方向で線形なリスト
- 単方向で循環なリスト
- 双方向で線形なリスト
- 双方向で循環なリスト
このうち、最初の「単方向で線形なリスト」は、前章で解説しました。本章では、残りの3タイプについて解説します。前章の内容を踏まえていますので、先に前章からお読みください。
まずは、「単方向で循環なリスト」です。
循環というのは、連結リストの末尾の要素の次に、先頭の要素が来るような構造を指します。イメージ図は次のようになります。
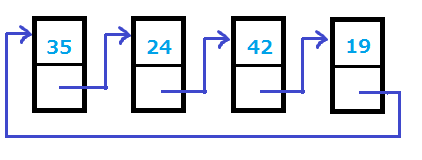 単方向循環リスト
単方向循環リスト
結局のところ、「単方向で線形なリスト」との違いは、末尾の要素の nextポインタが NULL ではなく、先頭の要素を指すようになったという点だけです。
このような特徴であるため、リスト全体の要素に対して何らかの処理を行うとき、どの要素までたどったら終わりなのかが判定しづらい問題があります。単方向線形リストでは、末尾の要素の nextポインタを NULL にしておくことで、末尾が明確になりました。
単方向循環リストでは、先頭の要素のメモリアドレスを覚えておき、nextポインタがこれと一致したときに、末尾まで行き着いたのだと判断するようにします。
前章の単方向線形リストの実装のように、先頭にダミーの要素があれば話は簡単です。nextポインタが、ダミーの要素のメモリアドレスと一致したら、その要素が末尾の要素です。
ダミーの要素を置くことは必須事項ではありませんが、ここではダミーの要素を使うことにします。
前章の終わりで使ったサンプルプログラムを、単方向循環リストに書き換えたものを示しておきます。
#include <stdio.h>
#include <string.h>
#include <stdlib.h>
static struct LinkedList_tag* create_list(void);
static void add_elem(struct LinkedList_tag* list, int value);
static void clear_list(struct LinkedList_tag* list);
static void print_list(struct LinkedList_tag* list);
static void delete_list(struct LinkedList_tag* list);
static struct LinkedList_tag* search_tail(struct LinkedList_tag* list);
// 連結リスト型
struct LinkedList_tag {
int value;
struct LinkedList_tag* next;
};
int main(void)
{
struct LinkedList_tag* list0;
struct LinkedList_tag* list1;
struct LinkedList_tag* list2;
// リストを作る
list0 = create_list();
list1 = create_list();
list2 = create_list();
// リストに要素を追加
add_elem( list0, 10 );
add_elem( list0, 20 );
add_elem( list1, 100 );
add_elem( list1, 200 );
add_elem( list2, 1000 );
add_elem( list2, 2000 );
// 各リストの中身を出力
print_list( list0 );
print_list( list1 );
print_list( list2 );
// リストを破棄
delete_list( list0 );
delete_list( list1 );
delete_list( list2 );
return 0;
}
/*
リストを作成する
戻り値:
作成されたリスト。
*/
struct LinkedList_tag* create_list(void)
{
struct LinkedList_tag* head = malloc( sizeof(struct LinkedList_tag) );
if( head == NULL ){
fputs( "メモリ割り当てに失敗しました。", stderr );
exit( 1 );
}
head->value = 0;
head->next = head; // 循環するので nextポインタは自分自身を指す
return head;
}
/*
リストを破棄する
引数:
list: 破棄するリスト。
*/
void delete_list(struct LinkedList_tag* list)
{
clear_list( list );
free( list );
}
/*
要素を追加する
引数:
list: 対象のリスト。
value: 追加する要素の数値データ。
*/
void add_elem(struct LinkedList_tag* list, int value)
{
// リストの末尾を探す
struct LinkedList_tag* tail = search_tail( list );
// 追加する要素を作る
struct LinkedList_tag* elem = malloc( sizeof(struct LinkedList_tag) );
if( elem == NULL ){
fputs( "メモリ割り当てに失敗しました。", stderr );
exit( 1 );
}
elem->value = value;
elem->next = list; // 末尾に追加するので、次の要素は先頭
// これまで末尾だった要素は、末尾から2番目の位置になる。
// そのため、nextメンバを書き換えて、新たな末尾の要素を指すようにする
tail->next = elem;
}
/*
要素を空にする
引数:
list: 対象のリスト。
*/
void clear_list(struct LinkedList_tag* list)
{
struct LinkedList_tag* p = list->next;
struct LinkedList_tag* prev = list;
while( p != list ){
// 削除する要素の1つ手前の要素の nextメンバを、
// 削除する要素の次の要素を指すように書き換える
prev->next = p->next;
// 要素は malloc関数で生成したので、free関数による解放が必要。
// 上記の prev->next = p->next よりも後で行わないと、不正なポインタが
// prev->next に代入されてしまうことに注意。
free( p );
p = prev->next;
}
}
/*
要素を出力する
引数:
list: 対象のリスト。
*/
void print_list(struct LinkedList_tag* list)
{
struct LinkedList_tag* p = list->next;
if( p == list ){
puts( "リストは空です。" );
return;
}
while( p != list ){
printf( "%d\n", p->value );
p = p->next;
}
}
/*
末尾の要素を探す
引数:
list: 対象のリスト。
戻り値:
連結リストの末尾にある要素を指すポインタ。
*/
struct LinkedList_tag* search_tail(struct LinkedList_tag* list)
{
struct LinkedList_tag* p = list;
while( p->next != list ){
p = p->next;
}
return p;
}
実行結果:
10
20
100
200
1000
2000
循環しない場合との違いは、以下の部分です。
- ダミーの先頭要素の nextポインタは、自分自身を指すように初期化されている
- リスト全体をたどるとき、終端判定は、ポインタがダミーの先頭要素のメモリアドレスと一致するかどうかになる
- 新しい要素を末尾に追加するとき、その要素の nextポインタは、ダミーの先頭要素になる
これら以外に違いはありません。
循環する連結リストは、リストを途中から辿り始めても、必ずすべての要素を辿ったうえで、元の位置まで戻ってこられる点が特徴的です。この特徴が活かせる場面では、循環するリストを使う価値があります。
双方向線形リスト
次は「双方向で線形なリスト」です。
単方向な連結リストが、後続の要素へのポインタ(nextポインタ) だけを持つのに対し、双方向な連結リストは、手前の要素へのポインタも持ちます。これによって、前後どちらの方向へでも連結をたどることが可能になります。
なお、双方向の連結リストは、双方向リストや重連結リストと呼ばれることもあります。
双方向線形リストのイメージ図は次のようになります。
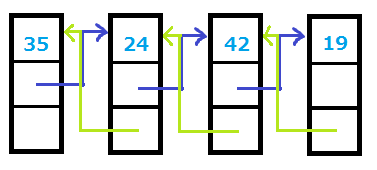 双方向線形リスト
双方向線形リスト
やや複雑ですが、単方向線形リストに対して、手前の要素へのポインタが追加されているだけです。1つ後ろの要素へのポインタを nextポインタと呼んでいたように、今後は1つ前の要素へのポインタは prevポインタと呼ぶことにします。
prevポインタを保持しなければならなくなったので、要素を表す構造体型にもメンバが1つ追加されます。
struct LinkedList_tag {
int value; // データ
struct LinkedList_tag* next; // 次の要素へのポインタ
struct LinkedList_tag* prev; // 手前の要素へのポインタ
};
次の要素がないとき nextポインタを NULL にするのと同様に、前の要素がないときには prevポインタを NULL にします。先頭にダミーの要素を置くのなら、ダミー要素の prevポインタはつねに NULL です。
単方向の連結リストと、双方向の連結リストとでは、ポインタのつなぎ変えが起こる場面での実装が変わってきます。prevポインタの方も書き換える必要があるため、前後両方の要素に影響を与えることになるので、複雑さが増しています。
ここでは、前章の最初のサンプルのように、動作確認が行える大きめのプログラムを示します。
#include <stdio.h>
#include <string.h>
#include <stdlib.h>
// コマンド
enum Cmd_tag {
CMD_ADD,
CMD_DELETE,
CMD_SEARCH,
CMD_CLEAR,
CMD_PRINT,
CMD_EXIT,
CMD_NUM
};
// コマンド文字列の種類
enum CmdStr_tag {
CMD_STR_SHORT,
CMD_STR_LONG,
CMD_STR_NUM
};
// コマンドの戻り値
enum CmdRetValue_tag {
CMD_RET_VALUE_CONTINUE,
CMD_RET_VALUE_EXIT,
};
// コマンド文字列
static const char* const CMD_STR[CMD_NUM][CMD_STR_NUM] = {
{ "a", "add" },
{ "d", "delete" },
{ "s", "search" },
{ "c", "clear" },
{ "p", "print" },
{ "e", "exit" }
};
static void init_head(void);
static void print_explain(void);
static void print_blank_lines(void);
static enum CmdRetValue_tag get_cmd(void);
static enum CmdRetValue_tag cmd_add(void);
static enum CmdRetValue_tag cmd_delete(void);
static enum CmdRetValue_tag cmd_search(void);
static enum CmdRetValue_tag cmd_clear(void);
static enum CmdRetValue_tag cmd_print(void);
static enum CmdRetValue_tag cmd_exit(void);
static void add_elem(int value);
static int delete_elem(int value);
static void clear_list(void);
static void print_list(void);
static struct LinkedList_tag* search_tail(void);
static struct LinkedList_tag* search_elem(int value);
static struct LinkedList_tag* delete_one_node(struct LinkedList_tag* node);
static void get_line(char* buf, size_t size);
// コマンド実行関数
typedef enum CmdRetValue_tag (*cmd_func)(void);
static const cmd_func CMD_FUNC[CMD_NUM] = {
cmd_add,
cmd_delete,
cmd_search,
cmd_clear,
cmd_print,
cmd_exit
};
// 連結リスト型
struct LinkedList_tag {
int value;
struct LinkedList_tag* next;
struct LinkedList_tag* prev;
};
static struct LinkedList_tag gHead; // 先頭の要素
int main(void)
{
init_head();
while( 1 ){
print_explain();
if( get_cmd() == CMD_RET_VALUE_EXIT ){
break;
}
print_blank_lines();
}
return 0;
}
/*
先頭要素を初期化
*/
void init_head(void)
{
gHead.value = 0;
gHead.next = NULL;
gHead.prev = NULL;
}
/*
説明文を出力
*/
void print_explain(void)
{
puts( "コマンドを入力してください。" );
printf( " 連結リストに要素を追加する: %s (%s)\n", CMD_STR[CMD_ADD][CMD_STR_SHORT], CMD_STR[CMD_ADD][CMD_STR_LONG] );
printf( " 連結リストから要素を削除する: %s (%s)\n", CMD_STR[CMD_DELETE][CMD_STR_SHORT], CMD_STR[CMD_DELETE][CMD_STR_LONG] );
printf( " 連結リストから要素を探す: %s (%s)\n", CMD_STR[CMD_SEARCH][CMD_STR_SHORT], CMD_STR[CMD_SEARCH][CMD_STR_LONG] );
printf( " 連結リストを空にする: %s (%s)\n", CMD_STR[CMD_CLEAR][CMD_STR_SHORT], CMD_STR[CMD_CLEAR][CMD_STR_LONG] );
printf( " 連結リストの中身を出力する: %s (%s)\n", CMD_STR[CMD_PRINT][CMD_STR_SHORT], CMD_STR[CMD_PRINT][CMD_STR_LONG] );
printf( " 終了する: %s(%s)\n", CMD_STR[CMD_EXIT][CMD_STR_SHORT], CMD_STR[CMD_EXIT][CMD_STR_LONG] );
puts( "" );
}
/*
空白行を出力
*/
void print_blank_lines(void)
{
puts( "" );
puts( "" );
}
/*
コマンドを受け付ける
*/
enum CmdRetValue_tag get_cmd(void)
{
char buf[20];
get_line( buf, sizeof(buf) );
enum Cmd_tag cmd = CMD_NUM;
for( int i = 0; i < CMD_NUM; ++i ){
if( strcmp( buf, CMD_STR[i][CMD_STR_SHORT] ) == 0
|| strcmp( buf, CMD_STR[i][CMD_STR_LONG] ) == 0
){
cmd = i;
break;
}
}
if( 0 <= cmd && cmd < CMD_NUM ){
return CMD_FUNC[cmd]();
}
else{
puts( "そのコマンドは存在しません。" );
}
return CMD_RET_VALUE_CONTINUE;
}
/*
addコマンドの実行
*/
enum CmdRetValue_tag cmd_add(void)
{
char buf[40];
int value;
puts( "追加する数値データを入力してください。" );
fgets( buf, sizeof(buf), stdin );
sscanf( buf, "%d", &value );
add_elem( value );
return CMD_RET_VALUE_CONTINUE;
}
/*
deleteコマンドの実行
*/
enum CmdRetValue_tag cmd_delete(void)
{
char buf[40];
int value;
puts( "削除する数値データを入力してください。" );
fgets( buf, sizeof(buf), stdin );
sscanf( buf, "%d", &value );
if( delete_elem(value) >= 1 ){
puts( "要素を削除しました。" );
}
else{
puts( "削除する要素は見つかりませんでした。" );
}
return CMD_RET_VALUE_CONTINUE;
}
/*
searchコマンドの実行
*/
enum CmdRetValue_tag cmd_search(void)
{
char buf[40];
int value;
puts( "探索する数値データを入力してください。" );
fgets( buf, sizeof(buf), stdin );
sscanf( buf, "%d", &value );
if( search_elem(value) == NULL ){
printf( "%d は連結リスト中に存在しません。\n", value );
}
else{
printf( "%d は連結リスト中に存在します。\n", value );
}
return CMD_RET_VALUE_CONTINUE;
}
/*
clearコマンドの実行
*/
enum CmdRetValue_tag cmd_clear(void)
{
clear_list();
return CMD_RET_VALUE_CONTINUE;
}
/*
printコマンドの実行
*/
enum CmdRetValue_tag cmd_print(void)
{
print_list();
return CMD_RET_VALUE_CONTINUE;
}
/*
exitコマンドの実行
*/
enum CmdRetValue_tag cmd_exit(void)
{
puts( "終了します。" );
return CMD_RET_VALUE_EXIT;
}
/*
要素を追加する
引数:
value: 追加する要素の数値データ。
*/
void add_elem(int value)
{
// リストの末尾を探す
struct LinkedList_tag* tail = search_tail();
// 追加する要素を作る
struct LinkedList_tag* elem = malloc( sizeof(struct LinkedList_tag) );
if( elem == NULL ){
fputs( "メモリ割り当てに失敗しました。", stderr );
exit( 1 );
}
elem->value = value;
elem->next = NULL; // 末尾に追加するので、次の要素は無い
elem->prev = tail; // 末尾に追加するので、前の要素はこれまでに末尾だった要素
// これまで末尾だった要素は、末尾から2番目の位置になる。
// そのため、nextメンバを書き換えて、新たな末尾の要素を指すようにする
tail->next = elem;
}
/*
要素を削除する
引数:
value: 削除する要素が持つ数値データ。
戻り値:
削除できた要素の個数を返す。
*/
int delete_elem(int value)
{
struct LinkedList_tag* p = gHead.next;
int count = 0;
while( p != NULL ){
if( p->value == value ){
p = delete_one_node( p );
++count;
}
else{
p = p->next;
}
}
return count;
}
/*
要素を空にする
*/
void clear_list(void)
{
struct LinkedList_tag* p = gHead.next;
while( p != NULL ){
p = delete_one_node( p );
}
}
/*
要素を出力する
*/
void print_list(void)
{
struct LinkedList_tag* p = gHead.next;
if( p == NULL ){
puts( "リストは空です。" );
return;
}
while( p != NULL ){
printf( "%d\n", p->value );
p = p->next;
}
}
/*
末尾の要素を探す
戻り値:
連結リストの末尾にある要素を指すポインタ。
*/
struct LinkedList_tag* search_tail(void)
{
struct LinkedList_tag* p = &gHead;
while( p->next != NULL ){
p = p->next;
}
return p;
}
/*
指定した値を持つ要素を探す
引数:
value: 探し出す要素が持つ数値データ。
戻り値:
先頭から連結リストをたどり、最初に見つけた value と同じ値を持つ要素のメモリアドレス。
見つからなかった場合は NULL を返す。
*/
struct LinkedList_tag* search_elem(int value)
{
struct LinkedList_tag* p = gHead.next;
while( p != NULL ){
if( p->value == value ){
return p;
}
p = p->next;
}
return NULL;
}
/*
1つの要素を削除する
引数:
node: 削除する要素を指すポインタ。
戻り値:
削除後に有効なポインタ。
*/
struct LinkedList_tag* delete_one_node(struct LinkedList_tag* node)
{
// 削除する要素の1つ手前の要素を保存しておく。
// 多少分かりやすくなるという意味もあるが、
// それよりも、このあと node は free関数で解放されるため、
// 誤って node->prev や node->next を参照しないようにすることに意味がある。
struct LinkedList_tag* const prev = node->prev;
// 削除する要素の1つ後ろの要素の prevポインタは、
// 削除する要素の1つ手前の要素を指すように書き換える。
// ただし、1つの後ろの要素が存在しない可能性を考慮しなければならない。
if( node->next != NULL ){
node->next->prev = prev;
}
// 削除する要素の1つ手前の要素の nextポインタを、
// 削除する要素の次の要素を指すように書き換える。
// node->next は NULL の可能性があるが、その場合、
// prev->next が NULL になるのが正解なので、
// そのまま代入してしまえば良い。
prev->next = node->next;
// 要素は malloc関数で生成したので、free関数による解放が必要。
// 上記の prev->next = node->next よりも後で行わないと、不正なポインタが
// prev->next に代入されてしまうことに注意。
free( node );
// 削除した要素の次にあった要素へのポインタを返す。これは NULL の可能性もある。
// ここで、node->next のように書くと、free関数で解放済みの領域をアクセスしてしまうので不適切。
return prev->next;
}
/*
標準入力から1行分受け取る
受け取った文字列の末尾には '\0' が付加される。
そのため、実際に受け取れる最大文字数は size - 1 文字。
引数:
buf: 受け取りバッファ
size: buf の要素数
戻り値:
buf が返される
*/
void get_line(char* buf, size_t size)
{
fgets(buf, size, stdin);
// 末尾に改行文字があれば削除する
char* p = strchr(buf, '\n');
if (p != NULL) {
*p = '\0';
}
}
内容は前章と同じですが、双方向線形リストになるように書き換えています。
一番難しいのは、要素を削除するときです。今回は、要素1つを削除する部分をdelete_one_node関数にまとめてあります。かなり詳細なコメントを加えてあるので、じっくり読んでみてください。
一箇所だけ NULLチェックを必要としている箇所があります。これは、末尾の要素を削除するケースでは、node->next が NULL であるため、node->next->prev を参照できないからです。
双方向の連結リストの利点は、リスト内のどの要素を参照しても、前後両方の要素をたどれることにあります。単方向のリストでは、要素の削除を行うときに常に手前の要素を保存しながら走査する必要がありましたが(前章参照)、そういう厄介事から解放されます。
単方向リストと比べると、prevポインタが増えたことにより、1要素ごとにポインタ変数1個分だけ、メモリを多く消費する欠点があります。現代的には、メモリに余裕がある環境が大半ですが、場合によってはやはり節約したいこともあります。
また、要素の挿入や削除の際に付け替えなければならないポインタの個数も増えていますから、挿入や削除の処理速度が、劣ります。
なお、.c と .h に実装しなおしたサンプル実装が、コードライブラリの ppps_int_list.c と ppps_int_list.h
双方向循環リスト
最後に、「双方向で循環なリスト」です。
nextポインタと prevポインタを両方持っており、かつ、最後の要素の次に最初の要素が来るように循環しているものを指します。循環の場合の特徴、双方向の場合の特徴はいずれも、これまでに見てきたとおりであり、それが組み合わさっただけです。
#include <stdio.h>
#include <string.h>
#include <stdlib.h>
// コマンド
enum Cmd_tag {
CMD_ADD,
CMD_DELETE,
CMD_SEARCH,
CMD_CLEAR,
CMD_PRINT,
CMD_EXIT,
CMD_NUM
};
// コマンド文字列の種類
enum CmdStr_tag {
CMD_STR_SHORT,
CMD_STR_LONG,
CMD_STR_NUM
};
// コマンドの戻り値
enum CmdRetValue_tag {
CMD_RET_VALUE_CONTINUE,
CMD_RET_VALUE_EXIT,
};
// コマンド文字列
static const char* const CMD_STR[CMD_NUM][CMD_STR_NUM] = {
{ "a", "add" },
{ "d", "delete" },
{ "s", "search" },
{ "c", "clear" },
{ "p", "print" },
{ "e", "exit" }
};
static void init_head(void);
static void print_explain(void);
static void print_blank_lines(void);
static enum CmdRetValue_tag get_cmd(void);
static enum CmdRetValue_tag cmd_add(void);
static enum CmdRetValue_tag cmd_delete(void);
static enum CmdRetValue_tag cmd_search(void);
static enum CmdRetValue_tag cmd_clear(void);
static enum CmdRetValue_tag cmd_print(void);
static enum CmdRetValue_tag cmd_exit(void);
static void add_elem(int value);
static int delete_elem(int value);
static void clear_list(void);
static void print_list(void);
static struct LinkedList_tag* search_tail(void);
static struct LinkedList_tag* search_elem(int value);
static struct LinkedList_tag* delete_one_node(struct LinkedList_tag* node);
static void get_line(char* buf, size_t size);
// コマンド実行関数
typedef enum CmdRetValue_tag (*cmd_func)(void);
static const cmd_func CMD_FUNC[CMD_NUM] = {
cmd_add,
cmd_delete,
cmd_search,
cmd_clear,
cmd_print,
cmd_exit
};
// 連結リスト型
struct LinkedList_tag {
int value;
struct LinkedList_tag* next;
struct LinkedList_tag* prev;
};
static struct LinkedList_tag gHead; // 先頭の要素
int main(void)
{
init_head();
while( 1 ){
print_explain();
if( get_cmd() == CMD_RET_VALUE_EXIT ){
break;
}
print_blank_lines();
}
return 0;
}
/*
先頭要素を初期化
*/
void init_head(void)
{
gHead.value = 0;
gHead.next = &gHead; // 循環するので nextポインタは自分自身を指す
gHead.prev = &gHead; // 循環するので prevポインタは自分自身を指す
}
/*
説明文を出力
*/
void print_explain(void)
{
puts( "コマンドを入力してください。" );
printf( " 連結リストに要素を追加する: %s (%s)\n", CMD_STR[CMD_ADD][CMD_STR_SHORT], CMD_STR[CMD_ADD][CMD_STR_LONG] );
printf( " 連結リストから要素を削除する: %s (%s)\n", CMD_STR[CMD_DELETE][CMD_STR_SHORT], CMD_STR[CMD_DELETE][CMD_STR_LONG] );
printf( " 連結リストから要素を探す: %s (%s)\n", CMD_STR[CMD_SEARCH][CMD_STR_SHORT], CMD_STR[CMD_SEARCH][CMD_STR_LONG] );
printf( " 連結リストを空にする: %s (%s)\n", CMD_STR[CMD_CLEAR][CMD_STR_SHORT], CMD_STR[CMD_CLEAR][CMD_STR_LONG] );
printf( " 連結リストの中身を出力する: %s (%s)\n", CMD_STR[CMD_PRINT][CMD_STR_SHORT], CMD_STR[CMD_PRINT][CMD_STR_LONG] );
printf( " 終了する: %s(%s)\n", CMD_STR[CMD_EXIT][CMD_STR_SHORT], CMD_STR[CMD_EXIT][CMD_STR_LONG] );
puts( "" );
}
/*
空白行を出力
*/
void print_blank_lines(void)
{
puts( "" );
puts( "" );
}
/*
コマンドを受け付ける
*/
enum CmdRetValue_tag get_cmd(void)
{
char buf[20];
get_line( buf, sizeof(buf) );
enum Cmd_tag cmd = CMD_NUM;
for( int i = 0; i < CMD_NUM; ++i ){
if( strcmp( buf, CMD_STR[i][CMD_STR_SHORT] ) == 0
|| strcmp( buf, CMD_STR[i][CMD_STR_LONG] ) == 0
){
cmd = i;
break;
}
}
if( 0 <= cmd && cmd < CMD_NUM ){
return CMD_FUNC[cmd]();
}
else{
puts( "そのコマンドは存在しません。" );
}
return CMD_RET_VALUE_CONTINUE;
}
/*
addコマンドの実行
*/
enum CmdRetValue_tag cmd_add(void)
{
char buf[40];
int value;
puts( "追加する数値データを入力してください。" );
fgets( buf, sizeof(buf), stdin );
sscanf( buf, "%d", &value );
add_elem( value );
return CMD_RET_VALUE_CONTINUE;
}
/*
deleteコマンドの実行
*/
enum CmdRetValue_tag cmd_delete(void)
{
char buf[40];
int value;
puts( "削除する数値データを入力してください。" );
fgets( buf, sizeof(buf), stdin );
sscanf( buf, "%d", &value );
if( delete_elem(value) >= 1 ){
puts( "要素を削除しました。" );
}
else{
puts( "削除する要素は見つかりませんでした。" );
}
return CMD_RET_VALUE_CONTINUE;
}
/*
searchコマンドの実行
*/
enum CmdRetValue_tag cmd_search(void)
{
char buf[40];
int value;
puts( "探索する数値データを入力してください。" );
fgets( buf, sizeof(buf), stdin );
sscanf( buf, "%d", &value );
if( search_elem(value) == NULL ){
printf( "%d は連結リスト中に存在しません。\n", value );
}
else{
printf( "%d は連結リスト中に存在します。\n", value );
}
return CMD_RET_VALUE_CONTINUE;
}
/*
clearコマンドの実行
*/
enum CmdRetValue_tag cmd_clear(void)
{
clear_list();
return CMD_RET_VALUE_CONTINUE;
}
/*
printコマンドの実行
*/
enum CmdRetValue_tag cmd_print(void)
{
print_list();
return CMD_RET_VALUE_CONTINUE;
}
/*
exitコマンドの実行
*/
enum CmdRetValue_tag cmd_exit(void)
{
puts( "終了します。" );
return CMD_RET_VALUE_EXIT;
}
/*
要素を追加する
引数:
value: 追加する要素の数値データ。
*/
void add_elem(int value)
{
// リストの末尾を探す
struct LinkedList_tag* tail = search_tail();
// 追加する要素を作る
struct LinkedList_tag* elem = malloc( sizeof(struct LinkedList_tag) );
if( elem == NULL ){
fputs( "メモリ割り当てに失敗しました。", stderr );
exit( 1 );
}
elem->value = value;
elem->next = &gHead; // 末尾に追加するので、次の要素は先頭
elem->prev = tail; // 末尾に追加するので、前の要素はこれまでに末尾だった要素
// これまで末尾だった要素は、末尾から2番目の位置になる。
// そのため、nextメンバを書き換えて、新たな末尾の要素を指すようにする
tail->next = elem;
}
/*
要素を削除する
引数:
value: 削除する要素が持つ数値データ。
戻り値:
削除できた要素の個数を返す。
*/
int delete_elem(int value)
{
struct LinkedList_tag* p = gHead.next;
int count = 0;
while( p != &gHead ){
if( p->value == value ){
p = delete_one_node( p );
++count;
}
else{
p = p->next;
}
}
return count;
}
/*
要素を空にする
*/
void clear_list(void)
{
struct LinkedList_tag* p = gHead.next;
while( p != &gHead ){
p = delete_one_node( p );
}
}
/*
要素を出力する
*/
void print_list(void)
{
struct LinkedList_tag* p = gHead.next;
if( p == &gHead ){
puts( "リストは空です。" );
return;
}
while( p != &gHead ){
printf( "%d\n", p->value );
p = p->next;
}
}
/*
末尾の要素を探す
戻り値:
連結リストの末尾にある要素を指すポインタ。
*/
struct LinkedList_tag* search_tail(void)
{
struct LinkedList_tag* p = &gHead;
while( p->next != &gHead ){
p = p->next;
}
return p;
}
/*
指定した値を持つ要素を探す
引数:
value: 探し出す要素が持つ数値データ。
戻り値:
先頭から連結リストをたどり、最初に見つけた value と同じ値を持つ要素のメモリアドレス。
見つからなかった場合は NULL を返す。
*/
struct LinkedList_tag* search_elem(int value)
{
struct LinkedList_tag* p = gHead.next;
while( p != &gHead ){
if( p->value == value ){
return p;
}
p = p->next;
}
return NULL;
}
/*
1つの要素を削除する
引数:
node: 削除する要素を指すポインタ。
戻り値:
削除後に有効なポインタ。
*/
struct LinkedList_tag* delete_one_node(struct LinkedList_tag* node)
{
// 削除する要素の1つ手前の要素を保存しておく。
// 多少分かりやすくなるという意味もあるが、
// それよりも、このあと node は free関数で解放されるため、
// 誤って node->prev や node->next を参照しないようにすることに意味がある。
struct LinkedList_tag* const prev = node->prev;
// 削除する要素の1つ後ろの要素の prevポインタは、
// 削除する要素の1つ手前の要素を指すように書き換える。
node->next->prev = prev;
// 削除する要素の1つ手前の要素の nextポインタを、
// 削除する要素の次の要素を指すように書き換える。
prev->next = node->next;
// 要素は malloc関数で生成したので、free関数による解放が必要。
// 上記の prev->next = node->next よりも後で行わないと、不正なポインタが
// prev->next に代入されてしまうことに注意。
free( node );
// 削除した要素の次にあった要素へのポインタを返す。
// ここで、node->next のように書くと、free関数で解放済みの領域をアクセスしてしまうので不適切。
return prev->next;
}
/*
標準入力から1行分受け取る
受け取った文字列の末尾には '\0' が付加される。
そのため、実際に受け取れる最大文字数は size - 1 文字。
引数:
buf: 受け取りバッファ
size: buf の要素数
戻り値:
buf が返される
*/
void get_line(char* buf, size_t size)
{
fgets(buf, size, stdin);
// 末尾に改行文字があれば削除する
char* p = strchr(buf, '\n');
if (p != NULL) {
*p = '\0';
}
}
双方向線形リストの実装と違って、nextポインタを辿っていく、あるいは prevポインタを辿っていくと、ダミー要素(gHead)に戻ってくるようになっています。
たとえば、リストを1周させるときの終了条件が、nextポインタが NULL かどうかではなく、ダミー要素に戻ってきたかどうかになっています。循環リストの場合は、終端が行き止まりではないので、そもそも NULL が登場することはありえません。
なお、.c と .h に実装しなおしたサンプル実装が、コードライブラリの ppps_int_clist.c と ppps_int_clist.h